Adversarial Texts with Gradient Methods
This page shows the complete result of our simple adversarial text generation method. You could find the source code and report here github/gongzhitaao/adversarial-text. Due to some reasons, the paper is withdrawn from arXiV. It is only available on GitHub.
1 Introduction
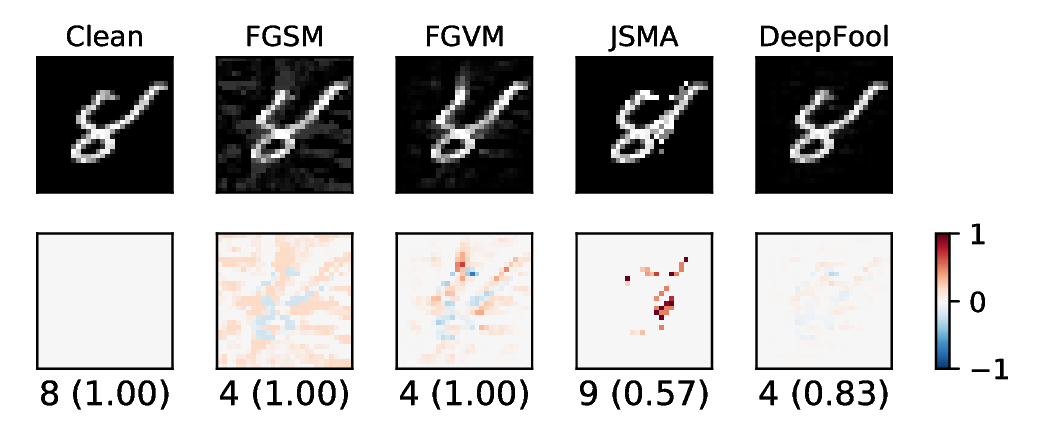
It has been shown in [6] that we can apply very subtle noise to images to trick deep learning into wrong prediction with very high confident. One example in shown in Figure 1. A set of adversarial images via different attacking algorithms are generated from a random image from MNIST dataset. The upper image in Clean column is the original clean image. The upper images in the following columns are adversarial images generated by the corresponding attacking algorithm, based on the first clean image, respectively. The lower image in each column is the differece between the adversarial image and the clean image, illustrated in heatmap. Below each column is the label predicted by the target model, along with probability in parenthesis. The algorithms demonstrated are FGSM [1], FGVM [2], JSMA [4] and DeepFool [3]. These are all gradient attacking methods.
2 Method
Our method is straightforward. We find the adversarial text in the embedding space, e.g. [5]. Part of the difficulty of generating adversarial texts is the discreteness of the input space. Instead of working in the raw input space, we first use the above method to find candidate adversarial embeddings in the embedding space, and use nearest neighbor to find the corresponding adversarial tokens. Since the embedding space is continuous, finding adversarials is the same as images. Similar to images, most of the time we only need to modify a couple tokens (out of hundreds) to change to fool different text models.
The downside of this method is that we do not have control over the quality (e.g., syntax, semantics) of the generated sentences.
3 Result
Due to the size of the dataset, we only show 100 samples for each parameter setting on the website. The rest samples could be downloaded. Note that some tokens in the clean dataset are different from the original piece of text, since these texts are also reconstructed by approximate nearest neighbor search for convenience. These does not affect the embedded vectors.
3.1 Fast Gradient Sign Method (FGSM)
This was proposed in [1]. The adversarial noise is computed as \(z = \epsilon \text{sign}\nabla L\).
| ε | 0.40 | 0.35 | 0.30 | 0.25 |
|---|---|---|---|---|
| IMDB | 0.1213 / 0.1334 | 0.1213 / 0.1990 | 0.1213 / 0.4074 | 0.1213 / 0.6770 |
| Reuters-2 | 0.0146 / 0.6495 | 0.0146 / 0.7928 | 0.0146 / 0.9110 | 0.0146 / 0.9680 |
| Reuters-5 | 0.1128 / 0.5880 | 0.1128 / 0.7162 | 0.1128 / 0.7949 | 0.1128 / 0.8462 |
3.2 Fast Gradient Value Method (FGVM)
This is a variant of FGSM, instead of gradients, FGVM uses the gradients directly. The noise is \(z = \epsilon\frac{\nabla L}{\|\nabla L\|_2}\).
| ε | 15 | 30 | 50 | 100 |
|---|---|---|---|---|
| IMDB | 0.6888 / 0.8538 | 0.6549 / 0.8354 | 0.6277 / 0.8207 | 0.5925 / 0.7964 |
| Reuters-2 | 0.7747 / 0.7990 | 0.7337 / 0.7538 | 0.6975 / 0.7156 | 0.6349 / 0.6523 |
| Reuters-5 | 0.5915 / 0.7983 | 0.5368 / 0.6872 | 0.4786 / 0.6085 | 0.4000 / 0.5111 |
3.3 DeepFool
This method is proposed in [3]. DeepFool iteratively finds the optimal direction in which we need to travel the minimum distance to cross the decision boundary of the target model. Although in non-linear cases, this optimality is not guaranteed, DeepFool works well in practice, and usually generates very subtle noise. In many of the examples, DeepFool alters the label of the text piece by replace only one word.
| ε | 20 | 30 | 40 | 50 |
|---|---|---|---|---|
| IMDB | 0.5569 / 0.8298 | 0.5508 / 0.7225 | 0.5472 / 0.6678 | 0.5453 / 0.6416 |
| Reuters-2 | 0.4416 / 0.6766 | 0.4416 / 0.5236 | 0.4416 / 0.4910 | 0.4416 / 0.4715 |
| Reuters-5 | 0.1163 / 0.4034 | 0.1162 / 0.2222 | 0.1162 / 0.1641 | 0.1162 / 0.1402 |
References
| [1] | I. J. Goodfellow, J. Shlens, and C. Szegedy. Explaining and Harnessing Adversarial Examples. ArXiv e-prints, December 2014. [ bib | arXiv ] |
| [2] | Takeru Miyato, Shin-ichi Maeda, Masanori Koyama, Ken Nakae, and Shin Ishii. Distributional smoothing with virtual adversarial training. stat, 1050:25, 2015. [ bib ] |
| [3] | Seyed-Mohsen Moosavi-Dezfooli, Alhussein Fawzi, and Pascal Frossard. Deepfool: a simple and accurate method to fool deep neural networks. CoRR, abs/1511.04599, 2015. [ bib | arXiv | http ] |
| [4] | Nicolas Papernot, Patrick McDaniel, Somesh Jha, Matt Fredrikson, Z. Berkay Celik, and Ananthram Swami. The limitations of deep learning in adversarial settings. CoRR, abs/1511.07528, 2015. [ bib | http ] |
| [5] | Jeffrey Pennington, Richard Socher, and Christopher Manning. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 1532--1543, 2014. [ bib ] |
| [6] | Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian J. Goodfellow, and Rob Fergus. Intriguing properties of neural networks. CoRR, abs/1312.6199, 2013. [ bib | http ] |